Text, audio, image, or video becomes training data for machine learning through data annotation, with the help of people and technology.
Building an AI or ML model that acts like a human requires large volumes of training data. For a model to make decisions and take action, it must be trained to understand specific information via data annotation.
But what is data annotation? This is the categorization and labeling of data for AI applications. Training data must be properly organized and annotated for a specific use case. With high-quality, human-powered data annotation, companies can build and improve AI implementations. The result is an enhanced customer experience solution such as product recommendations, relevant search engine results, computer vision, speech recognition, chatbots, and more.
There are several primary types of data: text, audio, image, and video, and many companies are taking full advantage of their offerings. In fact, according to the 2020 State of AI and Machine Learning report, organizations stated that they were using 25% more data types in 2020 in comparison to the previous year. With so many different industries and workspaces working with different data types, the need to increase investment in reliable training data has become more important than ever.
Let’s take a closer look at each annotation type, providing a real-world use case for each type that displays its success in assisting with data categorizing.
Text Annotation
Text annotation remains the most commonly used type, with 70% of companies surveyed in the machine learning report admitting that they rely heavily on text. Text annotation is essentially the process of using metadata tags to highlight keywords, phrases or sentences to teach machines how to properly recognize and understand human emotions through words. These highlighted “feelings” are used as training data for the machine to process and better engage with natural human language and digital text communication.
Accuracy means everything in text annotation. When annotations are inaccurate, they could lead to misinterpretation and make it more difficult to understand words in a specific context. Machines need to understand all potential phrasing of a certain question or statement based on how humans speak or interact via the internet.
Consider chatbots, for example. When a consumer phrases a question one way that the machine may be unfamiliar with, it can be difficult for the machine to reach the end point and provide a solution. The better text annotation involved, the more often a machine can carry out the time consuming tasks that a human being would usually take care of. Not only does this make for a better customer experience, but it can also help an organization meet its bottom line goals and utilize human resources to the best of its ability.
But are you familiar with the different forms of text annotation? Text annotations include a wide range of annotations like sentiment, intent, and query.
Sentiment Annotation
Sentiment analysis assesses attitudes, emotions, and opinions, to ultimately provide helpful insight that could potentially drive serious business decisions. That’s what makes it so important to have the right data from the start.
To obtain that data, human annotators are often leveraged as they can evaluate sentiment and moderate content on all web platforms. From reviewing social media and eCommerce sites, to tagging and reporting on keywords that are profane, sensitive, or neologistic, humans can be especially valuable in analyzing sentiment data because they understand the nuances and modern trends, slang and other uses of language that could make or break and organization’s reputation if the message is poorly stated and perceived.
Intent Annotation
As people converse more with human-machine interfaces, machines must be able to understand both natural language and user intent. Typically, when intent is not recognized by a machine, it will not be able to proceed with the request and will likely ask for the information to be rephrased. If the rephrasing of the question is still not perceived, the bot may hand the question over to a human agent, thus taking away the whole purpose of utilizing a machine in the first place.
Multi-intent data collection and categorization can differentiate intent into key categories including request, command, booking, recommendation, and confirmation. These categories make it easier for machines to understand the initial intent behind a query and are better routed to complete a request and find a resolution
Semantic Annotation
Semantic annotation covers the tagging of specific documents to concepts that are most relevant to the information. This involves adding metadata to documents that will enrich the content with concepts and descriptive words in an effort to provide greater depth and meaning to text.
Semantic annotation both improves product listings and ensures customers can find the products they’re looking for. This helps turn browsers into buyers. By tagging the various components within product titles and search queries, semantic annotation services help train your algorithm to recognize those individual parts and improve overall search relevance.
Named Entity Annotation
Named Entity Recognition (NER) is used to identify certain entities within text in an effort to detect critical information for large datasets. Information such as formal names, places, brand names and other identifiers are examples of what this annotation detects and organizes.
NER systems require a large amount of manually annotated training data. Organizations like Appen apply named entity annotation capabilities across a wide range of use cases, such as helping eCommerce clients identify and tag a range of key descriptors, or aiding social media companies in tagging entities such as people, places, companies, organizations, and titles to assist with better-targeted advertising content.
Multi-intent data collection and categorization can differentiate intent into key categories including request, command, booking, recommendation, and confirmation. These categories make it easier for machines to understand the initial intent behind a query and are better routed to complete a request and find a resolution.
Real World Use Case: Improving Search Quality for Microsoft Bing in Multiple Markets
Microsoft’s Bing search engine required large-scale datasets to continuously improve the quality of its search results – and the results needed to be culturally relevant for the global markets they served. We delivered results that surpassed expectations, allowing them to rapidly ramp up in new markets.
Beyond delivering project and program management, we provided the growth ability with high-quality data sets. And as the Bing team continues to experiment with new potential search quality experiences, we continue to develop, test and suggest solutions that will improve their data quality.
Read the case study in its entirety here. (Read the full case study here)
Named Entity Annotation
Audio Annotation
Audio recorded in a digital platform, regardless of its format, is perceived generally well today thanks to machine learning capabilities. This makes audio annotation, the transcription and time-stamping of speech data, possible for businesses. Audio annotation also includes the transcription of specific pronunciation and intonation, as well as the identification of language, dialect, and speaker demographics.
Every use case is different, and some require a very specific approach. For example: The tagging of aggressive speech indicators and non-speech sounds like glass breaking for use in security and hotline technology applications can be useful in emergency situations. Providing greater context of noises and sounds that occur within a conversation or event can make it easier to comprehend the situation to its fullest capability.
Real World Use Case: Dialpad’s transcription models leverage our platform for audio transcription and categorization
Dialpad improves conversations with data. They collect telephonic audio, transcribe those dialogs with in-house speech recognition models, and use natural language processing algorithms to comprehend every conversation. They use this universe of one-on-one conversation to identify what each rep–and the company at large–is doing well and what they aren’t, all with the goal of making every call a success. Dialpad had worked with a competitor of Appen for six months but were having trouble reaching an accuracy threshold to make their models a success. It took just a couple weeks for the change to bear fruit for Dialpad and to create the transcription and NLP training data they needed to make their models a success.
After working with an Appen competitor for six months, Dialpad found that it was having trouble reaching an accuracy threshold to make their models a success. After just a couple of weeks, Dialpad found success in trusting Appen to create the transcription and NLP training data they needed to make their models a success. Now, their transcription models leverage our platform for audio transcription and categorization and internal transcriptions verification and outputs of their models. (Click here to read the full case study)
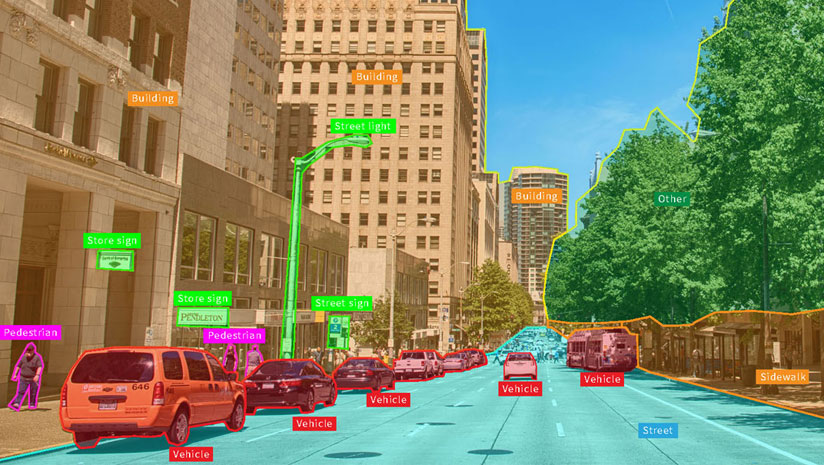
Image Annotation
Image annotation can be considered one of the most vital responsibilities a computer has in the digital age, as it’s given the opportunity to interpret the world through a visual lens or new, illuminated perspective. Image annotation is vital for a wide range of applications, including computer vision, robotic vision, facial recognition, and solutions that rely on machine learning to interpret images. To train these solutions, metadata must be assigned to the images in the form of identifiers, captions, or keywords.
From computer vision systems used by self-driving vehicles and machines that pick and sort produce, to healthcare applications that auto-identify medical conditions, there are many use cases that require high volumes of annotated images. Image annotation increases precision and accuracy by effectively training these systems.

Real World Use Case: Adobe Stock Leverages Massive Asset Profile to Make Customers Happy
One of Adobe’s flagship offerings, Adobe Stock, is a curated collection of high-quality stock imagery. The library itself is staggeringly large: there are over 200 million assets (including more than 15 million videos, 35 million vectors, 12 million editorial assets, and 140 million photos, illustrations, templates, and 3D assets).
While it may seem like an impossible task, it’s critical that every one of those assets becomes a discoverable piece of content. With this difficult situation, Adobe needed a fast and efficient solution.
Appen provided highly accurate training data to create a model that could surface these subtle attributes in both their library of over a hundred million images, as well as the hundreds of thousands of new images that are uploaded every day. That training data powers models that help Adobe serve their most valuable images to their massive customer base. Instead of scrolling through pages of similar images, users can find the most useful ones quickly, freeing them up to start creating powerful marketing materials. By utilizing human-in-the-loop machine learning practices, Abode has benefitted from a more effective, powerful and useful model that their customers can rely on.(Read the full case study here)
Video Annotation
Human-annotated data is the key to successful machine learning. Humans are simply better than computers at managing subjectivity, understanding intent, and coping with ambiguity. For example, when determining whether a search engine result is relevant, input from many people is needed for consensus. When training a computer vision or pattern recognition solution, humans are needed to identify and annotate specific data, such as outlining all the pixels containing trees or traffic signs in an image. Using this structured data, machines can learn to recognize these relationships in testing and production.
Real World Use Case: HERE Technologies Creates Data to Fine-Tune Maps Faster Than Ever
With a goal of creating three-dimensional maps that are accurate down to a few centimeters, HERE has remained an innovator in the space since the mid-’80s. They’ve always been in the business of giving hundreds of businesses and organizations detailed, precise and actionable location data and insights, and that driving factor has never been a second thought.
RHERE has an ambitious goal of annotating tens of thousands of kilometers of driven roads for the ground truth data that powers their sign-detection models. Parsing videos into images for that goal, however, is simply untenable. Annotating individual frames of a video is not only incredibly time consuming, but also monotonous and costly. Finding a way to fine-tune the performance of their sign-detection algorithms became a high priority, and Appen stepped up to the plate to deliver a solution.
ROur Machine Learning assisted Video Object Tracking solution presented a perfect opportunity to explore this lofty ambition. That’s because it combines human intelligence with machine learning to drastically increase the speed of video annotation.
After a few months of utilizing this solution, HERE feels confident that it has the opportunity to speed up the collection of data for their models. Video object tracking gives HERE the leverage to create more video of signs than ever, providing researchers and developers with essential information needed to better fine-tune their maps than ever before.
(Click here to read the full case study)
What Appen Can Do For You
Are you looking for a data annotation platform that provides that AI capability your organization needs to thrive? At Appen, we have Natural Language Processing (NLP) technology that is rapidly evolving based on the demand of interest in human-to-machine communications. We have the tools you need to take your business to the next level of the digital sphere.
Our data annotation experience spans over 20 years, providing our expertise in training data for countless projects on a global scale. By combining our human-assisted approach with machine-learning assistance, we give you the high-quality training data you need.
Our text annotation, image annotation, audio annotation, and video annotation will give you the confidence to deploy your AI and ML models at scale. Whatever your data annotation needs may be, our platform and managed service team are standing by to assist you in both deploying and maintaining your AI and ML projects.
Interested in learning more about our data annotation services? Contact us today and one of our highly trained team members will reach out to you as soon as possible.


