Building an AI or ML model that acts like a human requires large volumes of training data. For a model to make decisions and take action, it must be trained to understand specific information. Data annotation is the categorization and labeling of data for AI applications. Training data must be properly categorized and annotated for a specific use case. With high-quality, human-powered data annotation, companies can build and improve AI implementations. The result is an enhanced customer experience solution such as product recommendations, relevant search engine results, computer vision, speech recognition, chatbots, and more.
There are several primary types of data: text, audio, image, and video
Text Annotation
The most commonly used data type is text – according to the 2020 State of AI and Machine Learning report, 70% of companies rely on text. Text annotations include a wide range of annotations like sentiment, intent, and query.
Sentiment Annotation
Sentiment analysis assesses attitudes, emotions, and opinions, making it important to have the right training data. To obtain that data, human annotators are often leveraged as they can evaluate sentiment and moderate content on all web platforms, including social media and eCommerce sites, with the ability to tag and report on keywords that are profane, sensitive, or neologistic, for example.
Intent Annotation
As people converse more with human-machine interfaces, machines must be able to understand both natural language and user intent. Multi-intent data collection and categorization can differentiate intent into key categories including request, command, booking, recommendation, and confirmation.
Semantic Annotation
Semantic annotation both improves product listings and ensures customers can find the products they’re looking for. This helps turn browsers into buyers. By tagging the various components within product titles and search queries, semantic annotation services help train your algorithm to recognize those individual parts and improve overall search relevance.
Named Entity Annotation
Named Entity Recognition (NER) systems require a large amount of manually annotated training data. Organizations like Appen apply named entity annotation capabilities across a wide range of use cases, such as helping eCommerce clients identify and tag a range of key descriptors, or aiding social media companies in tagging entities such as people, places, companies, organizations, and titles to assist with better-targeted advertising content.
Real World Use Case: Improving Search Quality for Microsoft Bing in Multiple Markets
Microsoft’s Bing search engine required large-scale datasets to continuously improve the quality of its search results – and the results needed to be culturally relevant for the global markets they served. We delivered results that surpassed expectations. Beyond delivering project and program management, we provided the ability to grow rapidly in new markets with high-quality data sets. (Read the full case study here)
Audio Annotation
Audio annotation is the transcription and time-stamping of speech data, including the transcription of specific pronunciation and intonation, along with the identification of language, dialect, and speaker demographics. Every use case is different, and some require a very specific approach: for example, the tagging of aggressive speech indicators and non-speech sounds like glass breaking for use in security and emergency hotline technology applications.
Real World Use Case: Dialpad’s transcription models leverage our platform for audio transcription and categorization
Dialpad improves conversations with data. They collect telephonic audio, transcribe those dialogs with in-house speech recognition models, and use natural language processing algorithms to comprehend every conversation. They use this universe of one-on-one conversation to identify what each rep–and the company at large–is doing well and what they aren’t, all with the goal of making every call a success. Dialpad had worked with a competitor of Appen for six months but were having trouble reaching an accuracy threshold to make their models a success. It took just a couple weeks for the change to bear fruit for Dialpad and to create the transcription and NLP training data they needed to make their models a success. (Click here to read the full case study)
Image Annotation
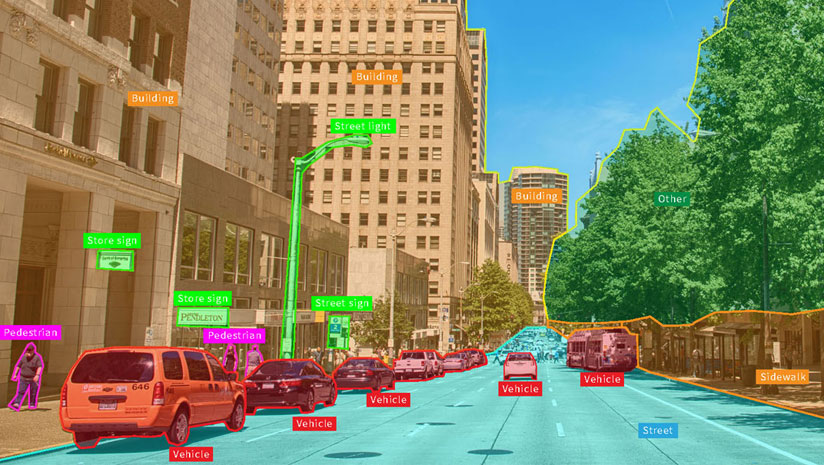
Image annotation is vital for a wide range of applications, including computer vision, robotic vision, facial recognition, and solutions that rely on machine learning to interpret images. To train these solutions, metadata must be assigned to the images in the form of identifiers, captions, or keywords.
From computer vision systems used by self-driving vehicles and machines that pick and sort produce, to healthcare applications that auto-identify medical conditions, there are many use cases that require high volumes of annotated images. Image annotation increases precision and accuracy by effectively training these systems.

Real World Use Case: Adobe Stock Leverages Massive Asset Profile to Make Customers Happy
One of Adobe’s flagship offerings is Adobe Stock, a curated collection of high-quality stock imagery. The library itself is staggeringly large: there are over 200 million assets (including more than 15 million videos, 35 million vectors, 12 million editorial assets, and 140 million photos, illustrations, templates, and 3D assets). Every one of those assets needs to be discoverable. Appen provided highly accurate training data to create a model that could surface these subtle attributes in both their library of over a hundred million images, as well as the hundreds of thousands of new images that are uploaded every day. That training data powers models that help Adobe serve their most valuable images to their massive customer base. Instead of scrolling through pages of similar images, users can find the most useful ones quickly, freeing them up to start creating powerful marketing materials. (Read the full case study here)
Video Annotation
Human-annotated data is the key to successful machine learning. Humans are simply better than computers at managing subjectivity, understanding intent, and coping with ambiguity. For example, when determining whether a search engine result is relevant, input from many people is needed for consensus. When training a computer vision or pattern recognition solution, humans are needed to identify and annotate specific data, such as outlining all the pixels containing trees or traffic signs in an image. Using this structured data, machines can learn to recognize these relationships in testing and production.
Real World Use Case: HERE Technologies Creates Data to Fine-Tune Maps Faster Than Ever
With a goal of creating three-dimensional maps that are accurate down to a few centimeters, HERE has remained an innovator in the space since the mid-’80s, giving hundreds of businesses and organizations detailed, precise and actionable location data and insights. HERE has an ambitious goal of annotating tens of thousands of kilometers of driven roads for the ground truth data that powers their sign-detection models. Parsing videos into images for that goal, however, is simply untenable. Our Machine Learning assisted Video Object Tracking solution presented a perfect solution to this lofty ambition. That’s because it combines human intelligence with machine learning to drastically increase the speed of video annotation. (Click here to read the full case study)
What Appen Can Do For You
At Appen, our data annotation experience spans over 20 years. By combining our human-assisted approach with machine-learning assistance, we give you the high-quality training data you need. Our text annotation, image annotation, audio annotation, and video annotation will give you the confidence to deploy your AI and ML models at scale. Whatever your data annotation needs may be, our platform and managed service team are standing by to assist you in both deploying and maintaining your AI and ML projects.


